FastAPI and pagination
Learn how to implement different pagination patterns with FastAPI
When reading the excellent FastAPI documentation, I noticed that there was something missing that is quite crucial in any real-world application: pagination. For information, pagination is a process to divide a large dataset into smaller chunks to prevent broking your API (you probably don’t want to return 10000 items in one row!). I don’t know if it’s intentional or just an oversight from the FastAPI author, but in any case, I decided to implement one myself. In this article, we will see the most common pagination patterns used: limit/offset, page/per_page, and cursor paginators.
To benefit from this article, you should already know how to use FastAPI. Read it at your own pace, it is a bit long but we will review different concepts such as dependency injections and middleware, you will see, there are many things to review/learn.
Setup the environment
I will use the latest major version of SQLAlchemy (2.X at the moment of writing) to illustrate pagination examples, but you will be able to easily transcript it to your favorite ORM. Also, you will need to have python3.8 or higher installed on your computer to test all the following snippets. And finally, to set up a test environment I will use poetry:
Note: the final source code is available on GitHub.
$ poetry new fastapi_paginatorYou should have a tree structure like the following:
fastapi_paginator/
├── fastapi_paginator
│ └── __init__.py
├── pyproject.toml
├── README.md
└── tests
└── __init__.pyYou can delete the tests folder we will not use it. Now, install the following dependencies:
$ poetry add fastapi uvicorn aiosqlite alchemicalYou may wonder about the alchemical package. It is a thin wrapper around SQLAlchemy which eases some aspects of its configuration (creating a database session, handling migration, etc…). You can see my presentation of this tool in the following link.
Your pyproject.toml file should be like this:
[tool.poetry]
name = "fastapi-paginator"
version = "0.1.0"
description = "Implement some pagination patterns for FastAPI"
authors = ["Your name <your@email.com>"]
readme = "README.md"
packages = [{include = "fastapi_paginator"}]
[tool.poetry.dependencies]
python = "^3.10"
fastapi = "^0.94.0"
uvicorn = "^0.21.0"
alchemical = "^0.6.0"
aiosqlite = "^0.18.0"Create a models.py module in the fastapi_paginator package with the following content:
from datetime import datetime
from typing import Optional
import asyncio
from alchemical.aio import Alchemical
from sqlalchemy.orm import Mapped, mapped_column
from sqlalchemy import String, Boolean, DateTime, func, select
db = Alchemical('sqlite:///file.db')
class Todo(db.Model):
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(50))
description: Mapped[Optional[str]]
done: Mapped[bool] = mapped_column(Boolean(), default=False)
created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True), default=func.now())
updated_at: Mapped[datetime] = mapped_column(DateTime(timezone=True), default=func.now(), onupdate=func.now())You will use this Todo model for our pagination examples.
Now create a schemas.py module inside the same package with the following content:
from datetime import datetime
from typing import Optional
from pydantic import BaseModel
class TodoSchema(BaseModel):
id: int
name: str
description: Optional[str]
done: bool
created_at: datetimeAnd now a main.py module again in the same package with this content:
import typing
from contextlib import asynccontextmanager
from fastapi import FastAPI, Depends
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
from .models import db, Todo
from .schemas import TodoSchema
async def get_session() -> typing.AsyncIterator[AsyncSession]:
async with db.Session() as session:
yield session
@asynccontextmanager
async def initialize_todos(_app) -> None:
await db.create_all()
async with db.begin() as session:
session.add_all([Todo(name=str(i), description=f'task-{i}') for i in range(50)])
yield
await db.drop_all()
app = FastAPI(lifespan=initialize_todos)
@app.get('/todos', response_model=typing.List[TodoSchema])
async def get_todos(session: AsyncSession = Depends(get_session)):
return [todo for todo in await session.scalars(select(Todo))]Notes:
- We use the new lifespan event handler to initialize some data to work with.
- We use SQLAlchemy asyncio capabilities.
- We list the
Todoitems without pagination to be sure it works.
Now go to http://127.0.0.1:8000/docs and checks that it works.
Limit-offset pagination
This is probably the simplest pagination pattern to implement. We will define two new query parameters in the view function, limit and offset, and use the offset/limit methods to select specific items.
@app.get('/todos', response_model=typing.List[TodoSchema])
async def get_todos(session: AsyncSession = Depends(get_session), limit: int = 100, offset: int = 0):
return [todo for todo in await session.scalars(select(Todo).limit(limit).offset(offset))]If you test it and change the limit to 10 for example, you will see now that pagination is in place, great! We can slightly ameliorate this by checking that query parameters are positive integers. This is especially useful for the limit parameter because a negative value will make the ORM return None and cause a 500 response.
from fastapi import Query
@app.get('/todos', response_model=typing.List[TodoSchema])
async def get_todos(
session: AsyncSession = Depends(get_session),
limit: int = Query(100, ge=0),
offset: int = Query(0, ge=0)
):
return [todo for todo in await session.scalars(select(Todo).limit(limit).offset(offset))]Ok, that is better, but now I want to show more information like the number of items, and also put the results under the key items. But I don’t want to change the schema of my Todo model to add this information. Imagine you have to do it with all the schemas you manage in an application, it will be quickly cumbersome.
For that purpose, we will define a generic schema adding the two pieces of information we want and combining it with our base schema, TodoSchema in our case. Add the following schema in the schemas.py module.
from typing import Optional, Generic, TypeVar, List
from pydantic import BaseModel, Field
from pydantic.generics import GenericModel
...
M = TypeVar('M')
class PaginatedResponse(GenericModel, Generic[M]):
count: int = Field(description='Number of items returned in the response')
items: List[M] = Field(description='List of items returned in the response following given criteria')Now update the main.py module like this:
from .schemas import TodoSchema, PaginatedResponse
...
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
session: AsyncSession = Depends(get_session),
limit: int = Query(100, ge=0),
offset: int = Query(0, ge=0)
):
return [todo for todo in await session.scalars(select(Todo).limit(limit).offset(offset))]If you go to the documentation at http://localhost:8000/docs, you will see that the example response and schemas are now updated.
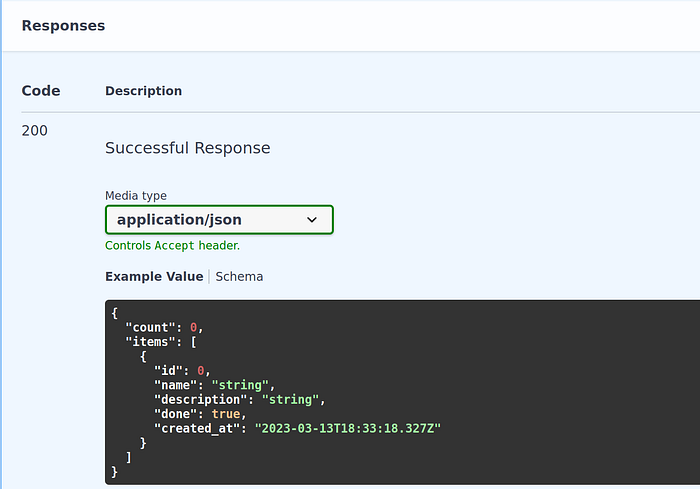
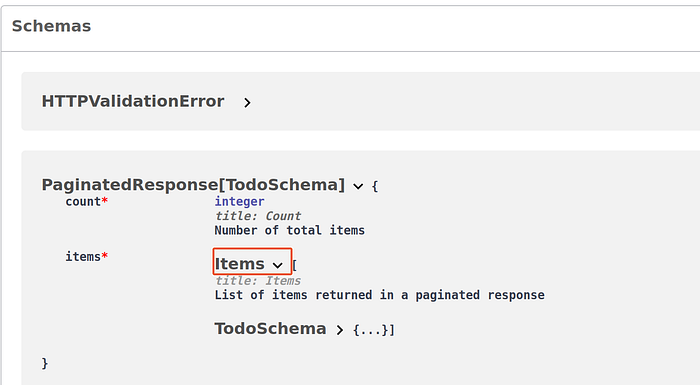
But if you try to test the code, it will… fail 🙃 This is expected since we still just return the list of todos without adding the new fields defined in the PaginatedResponse schema. To fix it, we can write the following code:
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
session: AsyncSession = Depends(get_session),
limit: int = Query(100, ge=0),
offset: int = Query(0, ge=0)
):
todos = [todo for todo in await session.scalars(select(Todo).limit(limit).offset(offset))]
return {
'count': len(todos),
'items': todos
}This will work, but there are two problems:
- First, if we have many endpoints with different schemas, we don’t want to repeat this logic, it would be better to define a function that includes logic.
- The way we count the items is not ideal if we have additional filters for example filtering todos done. We will always return the values limited by limit/offset parameters but they may not represent the total items present in the query set.
So this is what our helper function will look like and how we can use it in our view function.
from sqlalchemy import select, func, Select
...
async def paginate(query: Select, limit: int, offset: int) -> dict:
async with db.Session() as session:
return {
'count': await session.scalar(select(func.count()).select_from(query.subquery())),
'items': [todo for todo in await session.scalars(query.limit(limit).offset(offset))]
}
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
limit: int = Query(100, ge=0),
offset: int = Query(0, ge=0)
):
return await paginate(select(Todo), limit, offset)Notes:
- We don’t use the
get_sessiondependency in the view function anymore. Instead, we create it in our helper function. - The
paginatefunction takes the select statement at the first argument where we can apply all filters apart from limit/offset. With this statement, we can count items before using the pagination filter. - The way to count objects in SQLAlchemy 2.X differs from what you probably know from the previous versions. For more information on how I got this code, you can look at this GitHub issue or this StackOverflow question.
- There is a more advanced version of how to count items in the GitHub repository, feel free to look at it. Basically, the idea is to not load potentially related objects.
Now if we test the endpoint by passing a limit of 10, we will see that the count key equals 50, not 10 anymore, which represents the total number of Todo before pagination filters.
Phew, that was a lot of work, but we finally have a generic version that we can use in all our pagination views. You can take a breath before reading the rest if you want. 😉
Page-based pagination
This pagination model is probably the most used. We iterate results by page. It looks familiar from what we see on web applications. For example, in the CPython GitHub issues, if you look at the end of the page, you see that we can change pages.
Our first attempt will look similar to the limit-offset pagination, we will add two query parameters to the view function, page and per_page. We need to do some computations to know the limit and offset to use in the slice method, but nothing complicated. Here is what it looks like:
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
page: int = Query(1, ge=1),
per_page: int = Query(100, ge=0)
):
limit = per_page * page
offset = (page - 1) * per_page
return await paginate(select(Todo), limit, offset)The minimum value acceptable for the page parameter is 1 because… we don’t usually get the page 0. 😅 We can separate the logic to compute limit/offset from the view logic by using a (class) dependency.
class PaginatedParams:
def __init__(self, page: int = Query(1, ge=1), per_page: int = Query(100, ge=0)):
self.limit = per_page * page
self.offset = (page - 1) * per_page
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
q: PaginatedParams = Depends()
):
return await paginate(select(Todo), q.limit, q.offset)It looks better now, but to know if we are on the last page, we need to count items present in the response payload and compare it to the per_page query parameter. This is not ideal for users, it will be better if we have indications about the next and previous pages directly in the response. I’m thinking of something like Django Rest Framework pagination. To build URLs, we need some request context information available in the Request object. We can pass it as a dependency injection in the view function and use it in our paginate helper, but it will be cumbersome and repetitive. It will be better if we can access this information whenever we want and for that, we will use contextvars. Create a new middlewares.py module with the following content:
from contextvars import ContextVar
from starlette.requests import Request
from starlette.responses import Response
from starlette.middleware import Middleware
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
request_object: ContextVar[Request] = ContextVar('request')
class PaginationMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
request_object.set(request)
response = await call_next(request)
return response
middleware = [Middleware(PaginationMiddleware)]We create a middleware the Starlette way and we use it in the main.py module.
from .middlewares import middleware
...
app = FastAPI(lifespan=initialize_todos, middleware=middleware)We will update our schemas.py module to integrate the new fields we want in the response.
from pydantic import AnyHttpUrl
...
class PaginatedResponse(GenericModel, Generic[M]):
count: int = Field(description='Number of total items')
items: List[M] = Field(description='List of items returned in a paginated response')
next_page: Optional[AnyHttpUrl] = Field(None, description='url of the next page if it exists')
previous_page: Optional[AnyHttpUrl] = Field(None, description='url of the previous page if it exists')Now create a helpers.py module where we will define a Paginator class to help us build URLs to return in the response. We will also move our paginate helper function in this module.
from .middlewares import request_object
from .models import db
class Paginator:
def __init__(self, session: AsyncSession, query: Select, page: int, per_page: int):
self.session = session
self.query = query
self.page = page
self.per_page = per_page
self.limit = per_page * page
self.offset = (page - 1) * per_page
self.request = request_object.get()
# computed later
self.number_of_pages = 0
self.next_page = ''
self.previous_page = ''
def _get_next_page(self) -> typing.Optional[str]:
if self.page >= self.number_of_pages:
return
url = self.request.url.include_query_params(page=self.page + 1)
return str(url)
def _get_previous_page(self) -> typing.Optional[str]:
if self.page == 1 or self.page > self.number_of_pages + 1:
return
url = self.request.url.include_query_params(page=self.page - 1)
return str(url)
async def get_response(self) -> dict:
return {
'count': await self._get_total_count(),
'next_page': self._get_next_page(),
'previous_page': self._get_previous_page(),
'items': [todo for todo in await self.session.scalars(self.query.limit(self.limit).offset(self.offset))]
}
def _get_number_of_pages(self, count: int) -> int:
rest = count % self.per_page
quotient = count // self.per_page
return quotient if not rest else quotient + 1
async def _get_total_count(self) -> int:
count = await self.session.scalar(select(func.count()).select_from(self.query.subquery()))
self.number_of_pages = self._get_number_of_pages(count)
return count
async def paginate(query: Select, page: int, per_page: int) -> dict:
async with db.Session() as session:
paginator = Paginator(session, query, page, per_page)
return await paginator.get_response()Ok, there is some code, we will explain it all. First of all, the paginate function at the end of the module now takes the initial query parameters page and per_page. We will get rid of the dependency we used previously. It calls the Paginator class that computes the response via the get_response method.
For the Paginator class, if we look at the initialization method.
class Paginator:
def __init__(self, session: AsyncSession, query: Select, page: int, per_page: int):
self.session = session
self.query = query
self.page = page
self.per_page = per_page
self.limit = per_page * page
self.offset = (page - 1) * per_page
self.request = request_object.get()
# computed later
self.number_of_pages = 0
self.next_page = ''
self.previous_page = ''It takes the same arguments as the paginate function, computes the limit and offset from page and per_page, gets the request object from the ContextVar variable we defined previously, and, initializes three properties that will be computed later.
Now let’s look at the two last methods.
def _get_number_of_pages(self, count: int) -> int:
rest = count % self.per_page
quotient = count // self.per_page
return quotient if not rest else quotient + 1
async def _get_total_count(self) -> int:
count = await self.session.scalar(select(func.count()).select_from(self.query.subquery()))
self.number_of_pages = self._get_number_of_pages(count)
return countThe _get_total_count method computes the total count of items that will be returned giving the filtering criteria (in our case, there is none, but that could have been the case) and the number of pages the user will get by giving the per_page query parameter. For the latter, we use the method _get_number_of_page. The logic of this method is explained in this pseudo-code.
said we have 50 items and the user wants 11 items per page
let's compute the integer division of 50 by 11 and the modulo
50 // 11 = 4
50 % 11 = 6
So we 4 pages full of items and another page of 6 items, so at the end 5 pages
If the user requested 10 items per page
50 // 10 = 5
50 % 10 = 0
So we have 5 pages full of pages and nothing moreHope this is clear to you now. 🙂
The _get_next_page method computes the URL of the next page if one exists. It leverages the request.url property to compute it. The logic of the method is as follows:
If we have 5 pages and the user requests page 5 or more, we return None
If page is less than five, we add 1 to the page query parameter and return the new urlThe _get_previous_page method computes the URL of the previous page if one exists. The logic is as follows:
The first page is 1, so if the user requested this page, there is no previous page
Also, if we have 5 pages and the user requested page 7 (of course, it is a user error) we return nothing because page 6 is not a correct value
Otherwise we decrease one to the value of the page and return the new urlAnd finally the get_response method. Pay attention to the order of the instructions. _get_total_count must be placed at the beginning because it calculates the number_of_pages property which is useful for the following methods. 😄
Now let’s modify the main.py module with our new pagination function. You can remove the PaginatedParams class, we don’t need it anymore.
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
page: int = Query(1, ge=1), per_page: int = Query(100, ge=0)
):
return await paginate(select(Todo), page, per_page)You can test it and confirm it works as expected.
Cursor-based pagination
Last and not least, a cursor-based pagination. It is useful when you have very large datasets and data evolves quickly. It helps keep consistency in the data returned. For instance with the previous pagination strategies, if we have many items deleted from a previous page and navigate back to this page, we will probably see items from the page we left on the previous page. This is not possible with a cursor strategy because we get the items by taking as a base a numerical identifier that does not change like the id of our Todo model. For more information, you can read this article by the Slack team or the pagination documentation of Twitter API.
Generally, we don’t want to expose the numerical cursor used to query items for security purposes. We expose a string token representing that numerical information. In our case, we will mask the Todo id using the cryptography library. In the helpers.py module, add the following content:
from cryptography.fernet import Fernet
# In a production environment, you should generate it once
# and store it in a secure place
secret_key = Fernet.generate_key()
f = Fernet(secret_key)
def encode_id(identifier: int) -> str:
encoded_identifier = f.encrypt(str(identifier).encode())
return encoded_identifier.decode()
def decode_id(token: str) -> int:
encoded_identifier = f.decrypt(token.encode())
return int(encoded_identifier.decode())Like said in the comments, you must be careful about how we generate and store the secret key used to encode/decode identifiers in a production environment.
Now let’s slightly change our PaginatedResponse schema to add two new pieces of information, the next cursor, and the previous cursor if they exist. Also note that the count value now represents the number of items returned on a page and not the total number of items like in the previous pagination types because as said earlier, we have a dataset that evolves quickly, so computing this value is probably useless.
class PaginatedResponse(GenericModel, Generic[M]):
count: int = Field(description='number of items returned')
next_cursor: Optional[str] = Field(None, description='token to get items after the current page if any')
next_page: Optional[AnyHttpUrl] = Field(None, description='url of the next page if it exists')
previous_cursor: Optional[str] = Field(None, description='token to get items before the current page if any')
previous_page: Optional[AnyHttpUrl] = Field(None, description='url of the previous page if it exists')
items: List[M] = Field(description='List of items returned in a paginated response')After that, let’s look at how we implement our new Paginator class and its helper function paginate.
class Paginator:
def __init__(self, session: AsyncSession, query: Select, max_results: int, cursor: typing.Optional[str]):
self.session = session
self.query = query
self.max_results = max_results
self.cursor = cursor
self.request = request_object.get()
# computed later
self.next_cursor: typing.Optional[str] = None
self.previous_cursor: typing.Optional[str] = None
async def _get_next_todos(self, query: Select) -> typing.List[Todo]:
# if we requested 10 items and when fetching 10 + 1, we have 10 or less
# this means there are no more items, so we don't set self.next_cursor
initial_todos = [item for item in await self.session.scalars(query)]
if len(initial_todos) < self.max_results + 1:
return initial_todos
else:
todos = initial_todos[:-1]
self.next_cursor = encode_id(todos[-1].id)
return todos
async def get_response(self):
if self.cursor is None:
query = self.query.limit(self.max_results + 1)
else:
ident = decode_id(self.cursor)
query = self.query.where(Todo.id > ident).limit(self.max_results + 1)
todos = await self._get_next_todos(query)
return {
'count': len(todos),
'previous_page': await self._get_previous_page(),
'next_page': self._get_next_page(),
# order is important, self.previous_cursor is computed in method self._get_previous_page
'previous_cursor': self.previous_cursor,
'next_cursor': self.next_cursor,
'items': todos
}
def _get_url(self, cursor: str) -> str:
# we don't use request.url facilities because it will escape some characters (=) :D
url = self.request.url
return f'{url.scheme}://{url.netloc}{url.path}?max_results={self.max_results}&cursor={cursor}'
def _get_next_page(self) -> typing.Optional[str]:
if self.next_cursor is None:
return
return self._get_url(self.next_cursor)
async def _get_previous_todos(self, last_todo_id: int) -> typing.List[Todo]:
query = self.query.where(Todo.id < last_todo_id).order_by(Todo.id.desc()).limit(self.max_results)
todos = [todo for todo in await self.session.scalars(query)]
return todos
async def _get_first_todo(self) -> Todo:
results = await self.session.scalars(self.query)
return results.first()
async def _get_previous_url(self, todos: typing.List[Todo]) -> typing.Optional[str]:
if not todos:
return
# for the first page, the cursor is 1, but we select items > 1,
# so we will lose the first item, to avoid this we need to decrease the cursor by 1
cursor_todo_id = todos[-1].id
first_todo = await self._get_first_todo()
if first_todo.id == cursor_todo_id:
cursor_todo_id -= 1
self.previous_cursor = encode_id(cursor_todo_id)
return self._get_url(self.previous_cursor)
async def _get_previous_page(self) -> typing.Optional[str]:
if self.cursor is None:
return
else:
last_todo_id = decode_id(self.cursor)
previous_todos = await self._get_previous_todos(last_todo_id)
return await self._get_previous_url(previous_todos)
async def paginate(query: Select, max_results: int, cursor: typing.Optional[str]) -> dict:
async with db.Session() as session:
paginator = Paginator(session, query, max_results, cursor)
return await paginator.get_response()The code is a bit complex, but I tried to explain all the difficult parts in the comments. Also, it is probably not the best implementation, I’m thinking about how I compute the previous cursor but you have an idea of how you can implement yours.
And finally, the main.py module. Here we define two new query parameters to set the maximum number of items we want in a row and eventually a cursor to get the next results.
@app.get('/todos', response_model=PaginatedResponse[TodoSchema])
async def get_todos(
max_results: int = Query(100, ge=1),
cursor: str = Query(None)
):
"""Pagination based on a cursor model."""
return await paginate(select(Todo), max_results, cursor)Now, you can play with API and replace the cursor with the previous or next one found in the response to see the behavior.
Phew! This ends our pagination journey.
Bonus: Fastapi-pagination
While writing this blog I discover the library fastapi-pagination. A simple example of usage is as follows.
from sqlalchemy import select
from fastapi_pagination.ext.sqlalchemy_future import paginate
@app.get('/users', response_model=Page[UserOut])
def get_users(db: Session = Depends(get_db)):
return paginate(db, select(User).order_by(User.created_at)What is interesting about this library is that it implements the limit/offset and page/per_page pagination patterns for different kinds of ORM like SQAlchemy, Tortoise, ormar, etc…
Summary
When returning collections of items to users, we need to paginate the results to not break our APIs. In this article we saw three different strategies to implement pagination:
- Limit-offset: Most useful with small APIs.
- Page-per_page: The most common one usually applied because… it just works 😄
- Cursor: Used in large datasets evolving quickly and where we want to get items in the reverse order.
This is all for this article, hope you enjoy it. Take care of yourself and see you soon. 😁
If you like my article and want to continue learning with me, don’t hesitate to follow me here and subscribe to my newsletter on substack 😉